Bezplatný Quandl a jeho nasazení do „workflow“ hledání korelací
Většina algoritmických obchodníků se snaží využívat co největší množství dat a hledat souvislosti zapadající do jejich obchodních přístupů. V tomto článku bych proto rád upozornil na server Quandl nabízející bezplatně ohromné množství databází, které coby obchodníci můžeme využít.
Dnes je k dispozici množství informací a dat, která můžeme jako obchodníci využívat do svých algoritmů, skutečně veliké. Pochopitelně, že existuje řada placených zdrojů, ale i mnoho cest, jak dostat data zdarma. V druhé jmenované kategorii doporučuji nepřehlédnout www.quandl.com nabízející množství bezplatných databází extrémně snadno zakomponovatelných do našich „workflow“ a analytických nástrojů.
Quandl prakticky agreguje data z různých zdrojů a poskytuje k nim jednotný přístup. Pokud analyzujete data například v Excelu, tak nemusíte řešit, jak změnit kódy pro přístup k datům futures a měnám například poté, co jste doanalyzovali akciová data z yahoo a podobně. Quandl vám poskytne jednoduché, stále stejně volané rozhraní. Přičemž s veřejnými databázemi lze pracovat zdarma, navíc systém nabízí i komerční databáze. Přehled všech databází naleznete na této adrese: https://www.quandl.com/browse
Jak jsem na Finančníkovi již několikrát psal, sám jsem přešel z analýzy dat v Excelu na Python. A v souvislosti s daty z Quandl mi přijde příhodné ukázat, jak snadno se v těchto bezplatných nástrojích analyzují data a že z mého pohledu stojí zato jim věnovat pozornost. Tedy myšleno směrem k těm traderům, kteří jsou stejně jako já neprogramátoři. Právě nám, neprogramátorům, zprostředkovávají podobné nástroje možnosti, jak stále velmi efektivně pracovat s daty (a programátorům samozřejmě cesty, jak provádět datové analýzy velmi komplexně). Byť pochopitelně je třeba nastudovat základy syntaxe práce v daném prostředí – bez toho nelze pracovat ani v Excelu.
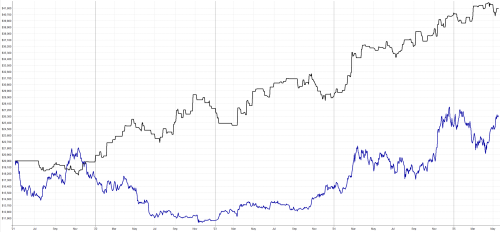
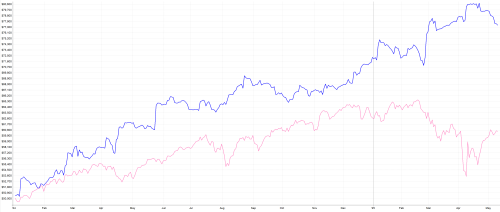
Pojďme se podívat, jak třeba získat odpověď na jednoduchou otázku – které akcie spolu vysoce korelují v některém z běžných akciových indexů? Tedy v zásadě rutinní výpočty nezbytné pro přístupy vycházející z intermarket analýzy.
Pro zjednodušení použiji index Dow Jones neobsahující příliš akcií. Přehled tickerů a jejich označení v Quandlu mohu získat například na této adrese: https://www.quandl.com/blog/useful-lists. Konkrétně zde je seznam akcií z indexu Dow Jones (k 11.11.2015), ale jak vidíte na výše linkované stránce, lze stejným způsobem použít výpočet na indexy typu S&P 500, Nasdaq, FTSE 100 a pochopitelně i další trhy (kdy u některých si přehled tickerů musím vytvořit sám).
Co tedy nyní potřebuji v Pythonu pro to, abych zjistil korelace mezi akciemi? Dopředu se omlouvám zkušeným programátorům za uveřejněný kód – je mi jasné, že to jde určitě i výrazně jednodušeji. Smyslem článku je ale ukázat, že k řešení se může snadno dostat právě i „poučený uživatel“/neprogramátor.
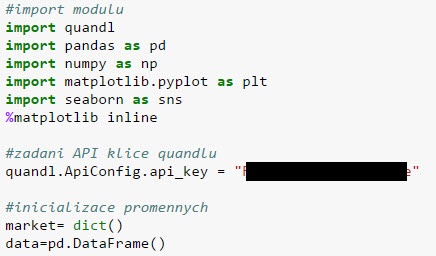
V Pythonu na začátku načtu moduly, které jsou bezplatně k dispozici a které připravili zkušení programátoři. Například modul pandas slouží k analýze finančních dat. „quandl.ApiConfig.api_key“ slouží k identifikaci do Quandlu (a získáte jej zdarma při registraci):
Ze stránek Quandlu jsem si stáhl csv obsahující tickery, které chci zkoumat. Načtení celého csv tak, abych s ním mohl pracovat v Pythonu, je otázka jednoho příkazu:
![]()
Nepatrně složitější smyčka, kdy vezmu tickery z načteného souboru a přes funkci quandl.get stáhnu data v uvedeném testovaném rozsahu z quandlu:

A jsem prakticky na konci. Stačí vypočíst korelaci mezi trhy. Na vše jsou funkce, takže jen zavolám funkci corr na proměnnou data, do které jsem si uložil data stažená z Quandlu:
![]()
Nyní mám korelace spočítané v proměnné corr. Mohu si je zobrazit jako číselnou matici, nebo třeba jednoduše jako heatmapu:
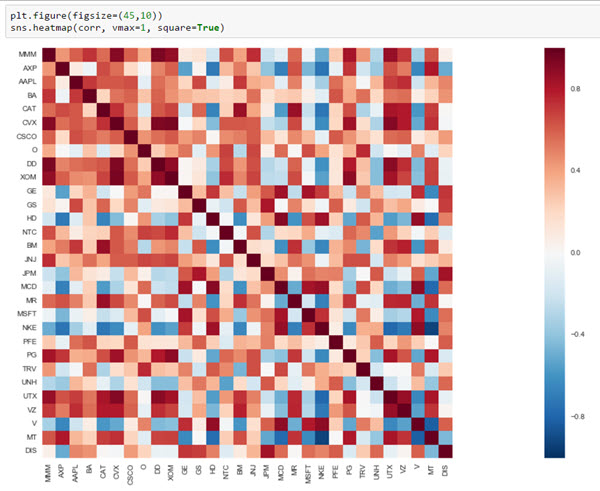
Teď ještě vybrat kombinace, které mají například korelaci vyšší než 0,9 a zároveň se nejedná o pár složený na obou stranách ze stejné akcie. Na to stačí dva řádky kódu:
![]()
V proměnné vyber mám pak vybrané trhy, které mezi sebou mají korelaci podle zadaných kritérií:

Tedy například MMM a CVX, MMM a DD, CVX a DD atd.
Pochopitelně, že pokud toto člověk studuje poprvé, tak některé syntaxe vypadají nesrozumitelně. Stejně, jako když se poprvé budeme snažit vytvořit nějaký kód v Excelovém VBA. Nicméně na uvedeném příkladu je zřejmé, že podobné datové analýzy jsou s uvedenými nástroji poměrně jednoduché a dají se naučit (sám jsem toho důkazem…). Ano, na řadu věcí lze používat části komerčních programů, ale za sebe si myslím, že základy analýzy dat patří mezi povinné učivo všech, kteří na nich chtějí vydělávat.
Petr Podhajský
Fulltime obchodník věnující se tradingu více než 20 let. Specializace na systematické strategie obchodované na futures a akciích. Oblíbený styl obchodování: stavba automatizovaných portfolio systémů, které využívá i při správě většího externího kapitálu.