Heron
-
Počet příspěvků
200 -
Registrace
-
Poslední návštěva
Vše publikováno uživatelem Heron
-
Odstrašující příklad neúspěšného obchodníka
příspěvek: Heron odpověděl na příspěvek uživatele albeon ve vláknu Futures
albeon: Hezký příspěvek. To co popisuješ jsou nevýhody diskréčního přístupu. S tím se budeš muset buď vyrovnat nebo se tomu můžeš elegantně vyhnout pomocí automatizovaného přístupu (AOS). Bohužel háček je v tom, že AOS má také své osobité nevýhody - hlavně ve fázi návrhu a testování. Záleží jen na tobě jaký přístup si zvolíš, co ti více vyhovuje. > „Existuje tu malá skupina těch, kterým to jde a ti líčí svoje úspěchy a tak trochu se vytahují, píšou "dělám každý den 2 hodiny a vydělávám miliony, je to naprostá paráda a je to jednoduchý." Já je naprosto chápu a neberu to zle, ale je to prostě matoucí. Jednak je blbost, že dělají jen 2 hodiny denně, to sice nějaké období třeba jde, ale jinak co jsem zatím zkoumal blíž, tak tradeři přizpůsobují obchodání celý svůj život, čtou si o něm, vyvíjejí nové postupy, prostě určitě to není ve výsledku 2 hodiny za den. A jednak to není jednoduché, to je taky omyl.“ Z vlastní zkušenosti ti můžu říct, že to blbost není (k těm milionům se nevyjadřuji, nevím za jaké období). Mě třeba zabírá vlastní intradenní obchodování cca 20 minut denně (když všechno funguje jak má) – zapnu AOS, během dne na něj několikrát kouknu, jestli všechno šlape a na konci dne zkontroluju a vypnu ho. Samozřejmě že než jsem AOS poprvé pustil na živý účet, tak jsem před tím věnoval tisíce hodin tomu, abych ten AOS udělal a otestoval, abych si prošel snad všechny slepé cesty, které nikam nevedou a abych udělal všechny chyby, které lze udělat a vyzkoušel mnoho "nadějných" systémů, které nefungovaly a abych si byl dostatečně "jistý" že bude systém i v budoucnu dávat zhruba stejně dobré výsledky. To všechno dělají diskréční obchodníci za pochodu během každodenní šichty v trzích, takže to má dopad i na jejich obchodování a občas při tom i zruší celý účet. Svůj život nepřizpůsobuji tradingu, ale naopak trading přizpůsobuji svému životu - a pokud je mi známo, tak to tak dělají skoro všichni úspěšní obchodníci. Když budeš přizpůsobovat svůj život tradingu, tak tě čeká dost smutný život - to si můžeš dovolit jen v začátcích a v rozumné míře. Život není jen o tradingu. Přesto že mě věci okolo tradingu dál zajímají a věnuju tomu dál dost času (pořád je co zlepšovat), tak pro mě není trading nic extra důležitého – je to prostě jen způsob jak vydělávat, a to způsob který mi vyhovuje. Někomu vyhovuje třeba založit si firmu a být 15 hodin každý den v práci a řešit problémy s lidmi. Někoho baví 6 hodin koukat na grafy. Já mám radši volný čas a abych ho teď měl, musel jsem hodně času nejprve investovat. Ty hodiny, které věnuji dalšímu „studiu“ bych do obchodování nepočítal, jsou to prostě hodiny volného času, které trávím tím co mě baví. Klidně je můžu trávit něčím jiným bez negativního dopadu na výsledky obchodování. Možná že někoho naplňuje představa, že bude nejlepší trader světa, ale já mám úplně jiné představy. A jestli to je jednoduché – pokud se bavíme o zapnout, zkontrolovat a vypnout, tak je to velmi jednoduché. Pokud se ale bavíme o návrhu a implementaci kvalitního AOS, tak to vůbec není ani trochu jednoduché. Samozřejmě i diskréční obchodníci můžou obchodovat jen 2 hodiny denně, ale také tomu před tím věnovali mnoho a mnoho hodin. Buď obchodují intradenně jen část seance nebo můžou třeba obchodovat na denních/týdenních grafech a jen kontrolovat a upravovat pozice během pár minut denně. Snad už to pro tebe teď nebude tolik matoucí. -
Diskuze k článku: 12. Support a resistance
příspěvek: Heron odpověděl na příspěvek uživatele Financnik.cz ve vláknu Finančník.cz - diskuze k článkům
Kingie: Naprostý souhlas. Ten odkaz na fxstreet jsem dal proto, že tam jsou vytříděny čistě články od SS a nemusí to hledat mezi ostatními autory z Lesson From the Pros z toho linku co dal Sinuhet. Kuba69: Zdá se, že se v tom už celkem orientuješ a že tě zajímají hlubší souvislosti. Pokud bych ti směl něco doporučit, tak doporučuji přečíst si knížku „Jason Alan Jankovsky – Time Compression Trading“ (k nalezení mimo jiné na uloz.to), zejména první polovinu. To by mohlo být to správné pošťouchnutí. Není to sice o S/D, ale určitě se ti to bude hodit. Jinak k těm S/D – žádná sada pravidel (libovolně velký počet pravidel) ti nezaručí 100% úspěšnost při odhadování, který S/D je ten správný, protože žádný z nich z principu nemůže být 100% správný. Nejsou dobré a špatné S/D, ale spojité kontinuum od nejsilnějších po nejslabší. Každý z nich ale může selhat, liší se jen v pravděpodobnosti selhání – ta vychází jednak z pravidel SS a jednak z náhody (např. nějaká jednorázová událost, vstup nějakého velkého hráče, souhra okolností apod). Vždycky se může situace změnit a sebekrásnější S/D selže nebo se cena zastaví a odrazí někde jinde. Důležité je, aby vliv pravidel byl větší než vliv náhody. SS má dlouholetou praxi ve vybírání těch na silnější straně spektra, zatímco ty ještě občas vybíráš i ty z prostředka + u obou vliv náhody. Některé S/D levely z grafů od SS taky potom nezafungovaly. Zkus pro začátek hledat/kontrolovat S/D na vyšším time frame, než na jakém obchoduješ. Jenda 701: Díky. Jestli můžu doporučit ještě jednu knížku, tak je to ta stejná, co jsem právě doporučil pro Kuba69. Velmi užitečné čtení. Na stejném místě najdeš i dvě další knížky od JAJ, "The Art of the Trade" taky není marná, hlavně 5. kapitola "The Meaning of Life". -
Diskuze k článku: 12. Support a resistance
příspěvek: Heron odpověděl na příspěvek uživatele Financnik.cz ve vláknu Finančník.cz - diskuze k článkům
Kuba69: Lituji, ale zrovna se mi moc nechce psát „další článek“ na jakékoliv téma. Je něco konkrétního, co by tě zajímalo? Pokud tě zajímá přístup Sama Seidena, tak doporučuji čerpat přímo ze zdroje. Kromě již uváděných odkazů v tomhle vlákně můžeš začít tady: Archiv článků SS z let 2007-2010 (aktualizované, po rozkliknutí roku a měsíce se zobrazí odkazy na jeho články): www.fxstreet.com/education/trading-strategies/lessons-from-the-pros/2010/ Archiv webinářů SS: www.fxstreet.com/search/contributors/authors/author.aspx?id=5766b88a-1a31-4102-8221-e9bf77216d2f Doporučuji přečíst si postupně všechny články. Hodně se to sice opakuje, ale obsahují užitečné informace nejen k S/D zónám. Taky si to můžeš nechat zdarma posílat emailem v rámci Online Trading Academy – Lesson From the Pros. Protože to SS vyučuje za $$$ v rámci OTA, tak samozřejmě neodkryje všechny karty do detailů, ale to podstatné se dozvíš. Dají se také vygooglit poznámky absolventů OTA a tam se lze dočíst další užitečné detaily, na některých zahraničních trading forums jsou vlákna na tohle téma atd. Přístup SS vychází z praxe pitového obchodníka a rozhodně nic zbytečně nekomplikuje. Jeho přístup je logický, jednoduchý a robustní, aplikovatelný na libovolný trh i time frame. Mnohem důležitější je, že jde o obchodování s vysokou pravděpodobností úspěchu, nízkým rizikem a vysokým profitem (ve srovnání s podstupovaným rizikem), takže zvyšuješ profit faktor na všech frontách. Díky obecnosti a nezávislosti na time frame si také můžeš zvolit „oportunity“ jakou potřebuješ – kolik obchodů za nějaké časové období chceš dělat. Nejdůležitější je ale obecnější přístup k obchodování - o čem trh a obchodování vlastně je a jak z trhu dostat peníze druhých na svůj účet. -
Studium - zadost o radu
příspěvek: Heron odpověděl na příspěvek uživatele DavidP ve vláknu Dotazy a odpovědi - jen archiv [POUZE KE ČTENÍ]
raztos: Nejsem a pod tímhle nickem nikam jinam nepřispívám, ani pod žádným jiným nickem. Volume osobně považuji za důležitou informaci. Na základě PA, volume a bid/ask informací samozřejmě je možné obchodovat. -
Diskuze k článku: Automatické obchodní systémy: životnost a risk-management (1/3)
příspěvek: Heron odpověděl na příspěvek uživatele Financnik.cz ve vláknu Finančník.cz - diskuze k článkům
Olympusko: > Ale je korektní ptát se, co byste mohli udělat pro boj s falešným nalezením závislostí? Já se domnívám že ano, a že nalezení odpovědi změní tvůj pohled na svět (nejen) tradingu. Jak už jsem několikrát zmínil, tak rozumím tvému úhlu pohledu a přístupu, protože jsem měl dříve velmi podobný. Nemám nic proti použití různých statistických metod, ale to že šplháme po žebříku rychle nahoru ještě neznamená, že jsme ho opřeli o správnou zeď. Mám takový velmi vtíravý dojem, že všechno tohle souvisí s tím, jak vnímáme kauzalitu a jak jí rozumíme. V příloze přikládám jeden článek na toto téma. Je sice o ekonomii a je bez statistických vzorců, ale jsem přesvědčen, že ti nebude dělat problém pochopit pointu a jak se to vztahuje k tradingu a přístupu k tvorbě OS. Mířím k něčemu takovému, co George Soros chtěl říci svou teorií reflexivity. Osobně jsem to od Sorose nepobral, protože jeho styl výkladu byl pro mě zmatený (nebo jsem se tenkrát moc nesoustředil). Věnoval tomu kousek v knize Soros o Sorosovi a mnohem více v knize Nové paradigma pro finanční trhy. Za nějaký čas jsem narazil na totéž (nebo něco velmi podobného), ale vysvětlené někým jiným z jiného úhlu pohledu a na 2 stránkách A4 (plus několik stránek omáčky). To mě posunulo vpřed mnohem více, než cokoliv jiného a od té doby na to jdu jinak a s mnohem lepšími výsledky. Ohledně přínosu statistiky se shodujeme - používat ano, ale korektně a především na správném místě. Jen se trochu neshodujeme na tom co je správné místo, ale to je OK. Totéž platí i o tom ostatním - metody atd. Asi vnímáme kauzalitu každý trochu jinak nebo jsou jiné naše znalosti kauzality na trzích. Nebo je to všechno nesmysl, ale to nevadí, hlavně když mi to sype prachy :) -
Diskuze k článku: Automatické obchodní systémy: životnost a risk-management (1/3)
příspěvek: Heron odpověděl na příspěvek uživatele Financnik.cz ve vláknu Finančník.cz - diskuze k článkům
Rob99: > To vase vlakno jak stavite atomovou ponorku na obezne draze vam necham... Robe, to vlákno není moje, jen jsem ho založil - a to nikoliv z důvodů, abych stavěl ponorku (mimochodem hezké přirovnání) :) Hlavní důvod byl abych pořád někomu nenabourával jeho vlákno svými dlouhými příspěvky nebo abych pořád nemusel hledat vlákno, kam by se případný příspěvek hodil. pro všechny: Berte prosím vlákno "Střípky souvislostí" jako vlákno "Různé" a dávejte tam klidně svoje příspěvky, které buď nikam nezapadají nebo naopak zapadají kamkoliv a nechce se vám kvůli tomu zakládat další vlákno. -
Diskuze k článku: Automatické obchodní systémy: životnost a risk-management (1/3)
příspěvek: Heron odpověděl na příspěvek uživatele Financnik.cz ve vláknu Finančník.cz - diskuze k článkům
kuzmic: Souhlasím s tebou. šlo jen o hrubý nástřel - ukázat nad čím by se taky mělo trochu pouvažovat. Rozhodně můj příspěvek nebyl míněn jako souhrn životní moudrosti a ani jsem nad ním 20 let nepřemýšlel. Prostě jsem napsal co mě zrovna napadlo bez snahy o úplnost, exaktnost atd. Sebedelší příspěvek bude obsahovat jen konečný počet slov a myšlenek a vždycky najdeš něco, co tam nebude a mělo by, nebo to lze pojednat nějak jinak atd. O to myslím tak nějak neběží. To ať si každý vyřeší sám pro sebe jak hluboko a široko se nad tím chce nebo nechce zamýšlet a jak se na to bude dívat. Cokoliv co jsem napsal berte jen jako případnou inspiraci a ne pokus o konečnout teorii všeho a vrchol věškeré moudrosti :) Olympusko: Těším se :) -
Diskuze k článku: Automatické obchodní systémy: životnost a risk-management (1/3)
příspěvek: Heron odpověděl na příspěvek uživatele Financnik.cz ve vláknu Finančník.cz - diskuze k článkům
Rob99: Nevím kam míříš s tou ponorkou na oběžné dráze. Moje sytémy jsou řekl bych až "trapně" jednoduché. Pokud se podíváš na nějaké moje příspěvky v jiných vláknech, tak uvidíš že "psychologie davu" byla zakomponována v příspěvku o behaviorální psychologii, v příspěvku o kvalitě S/R ala Sam Seiden, v příspěvku o přístupu ala OrderFlow Analytic apod. Takže ne že bych si toho nebyl vědom a ne že bych to nevyužíval. Jen se na to dá dívat z různých úhlů a nepužívám křížení EMA s 22 podsystémy, protože to je zase mimo moje chápání :) Pokud jde o některé moje jiné příspěvky, tak se buď snažím poukázat na některá místa, odkud může vyskočit nečekaný problém, nebo jen tak poukazuji na něco, co mi připadá zajímavé kvůli nějakým souvislostem. Nemusí to být nutně oblast, kterou praktikuju, ale bývají to oblasti které jsem dříve trochu prozkoumal. Jinak k tvému systému a přístupu - nijak ho nekritizuju. Dělej co sám uznáš za vhodné a rozumné. Moje výhry se neodvíjí od tvého systému nebo přístupu, ale od mého systému a přístupu. To co se osvědčilo mě, nemusí být nutně nejlepší volba pro všechny - byť doufám že to je dostatečně univerzální, minimálně pro inspiraci nebo zamyšlení. -
Diskuze k článku: Automatické obchodní systémy: životnost a risk-management (1/3)
příspěvek: Heron odpověděl na příspěvek uživatele Financnik.cz ve vláknu Finančník.cz - diskuze k článkům
honza 27: Ano - proč by ne, může zahrnovat cokoliv co funguje. Ano - mám a obchoduji a spadá do 1) a 2) -
Diskuze k článku: Automatické obchodní systémy: životnost a risk-management (1/3)
příspěvek: Heron odpověděl na příspěvek uživatele Financnik.cz ve vláknu Finančník.cz - diskuze k článkům
BobSk: Nevidím důvod proč by tvůj systém nemohl být kvalitní. Stejně tak nevidím jasný "důkaz" že kvalitní je - to můžeš posoudit jen ty. Kvalitní a funkční systém nemusí nezbytně fungovat na všech trzích - pokud byl navržen specificky na jeden konkrétní trh. Hypotetický příklad: řekněme že existuje nějaký fundamentální vztah třeba mezi akciemi a dluhopisy. Ty třeba zjistíš, že trh s dluhopisy zavírá v 15:00 ale akcie se obchodují do 16:00 resp 16:15, a že pokud se dluhopisy chovaly nějak, tak po zavření se akcie chovají nějak. Pokud by tam byla nějaká opodstatněná souvislost (nebo aspoň by to tak podle testů vypadalo), tak můžeš udělat systém který tuto jedinečnou souvislost bude systematicky využívat např. při obchodvání futures na indexy. Je jasné, že na ropě nebo na kukuřici takový systém fungovat nebude, leda čistě náhodou. Zdůrazňuji, že jde o hypotetický příklad a je jasné, že tenhle typ edge by brzo začal každý využívat a postupně by vymizelo. Pokud ale tvůj systém využívá nějakou obecnější věc, která by měla být nezávislá na konkrétním trhu, tak pak by měl dobrý systém fungovat víceméně stejně na všech trzích (samozřejmě pokud je tak navržený tj. zohledňuje např. volatilitu každého trhu atd.). Pokud malá změna ve vstupních parametrech způsobí velikou změnu ve výstupních parametrech, pak systém není robustní a pravděpodobně jde o přeoptimalizaci - pokud ovšem nemluvíme o případu z prvního odstavce, kde je samozřejmě rozdíl mezi 15:00, 12:00 a 16:00 času - je to nastaveno třeba specificky pro 15:05 hodin. a pro nastavení 14:45 to prostě nefunguje a ani by to nemělo fungovat. -
Diskuze k článku: Co mají společného trading a Bůh
příspěvek: Heron odpověděl na příspěvek uživatele Financnik.cz ve vláknu Finančník.cz - diskuze k článkům
Co mají společného Bůh (nebo víra jako taková) a trading, to opravdu nevím. Napadá mě ale jedna věc, kterou mají společnou náboženství a trading - a to je CARGO KULT. Většina příznivců obojího pouze napodobují (provádí rituály a uctívání) někoho bez jakéhokoliv pochopení podstaty a souvislostí - imitují vnější stránku věci. V náboženství čekají spásu ducha (nebo ať si každý dosadí co chce), v tradingu očekávají, že napodobováním něčí strategie získají svatý grál nebo aspoň funkční strategii. Upřímně, kdo z náboženských příznivců ŽIJE tak, jak mu radí Bible nebo jiné svaté knihy (např. láska k bližnímu, soucit a tolerance), a kdo jen napodobuje vnější stránku věci? Totéž platí v tradingu – většina se jen snaží napodobovat úspěšné tradery z vnější stránky věci, ale uniká jim ta důležitá vnitřní část. Takže říkejte dál svá přání do mikrofonů z kokosových skořápek, dělejte vysílačky z bambusu, stavějte letadla ze slámy a jednoho dne budou určitě vaše přání vyslyšena a přiletí Santa Klaus a s ním hromady dobrých konzerv. Stačí jen opakovat iracionální rituály, věřit a čekat. Nebo se postavit na vlastní nohy a stát se dalším úspěšným traderem nebo dalším Budhou ... PS: Nechci se tím nijak dotknout nikoho, kdo je věřící či příznivcem jakéhokoliv náboženství, jen poukazuju na to, že když dva dělají totéž, nemusí být výsledkem totéž. Cargo kult je běžně provozován v mnoha jiných oblastech života např. v managementu apod. -
Diskuze k článku: Automatické obchodní systémy: životnost a risk-management (1/3)
příspěvek: Heron odpověděl na příspěvek uživatele Financnik.cz ve vláknu Finančník.cz - diskuze k článkům
sals3r0: Díky za odpověď. Technickou stránku problému ponechme stranou. Byl to jen takový myšlenkový experiment. Nejspíš by to bylo opravdu velmi těžké udělat tak, aby to bylo čistě náhodné a přitom to mělo všechny parametry skutečného trhu – proto jsem záměrně napsal slovo „všechny“ do uvozovek – myslel jsem jen takové, abys nepoznal podvrh. Jakmile totiž dokážeš poznat náhodný podvrh od skutečnosti, tak tím zároveň dokážeš odhalit jaký je mezi nimi rozdíl tj. nenáhodnou složku – a to je to co potřebuješ najít pro funkční systém. Patternů tam samozřejmě bude mnoho a mnoho, všechny ale budou pro reálné využití k ničemu. Podstatu mojí narážky jsi ale zřejmě pochopil viz tvůj závěr proč je krátká životnost obchodních systémů: buď nikdy žádné edge nevyužívaly nebo se vytratilo s časem. Přitom téměř všichni byli přesvědčeni, že mají skutečné trvalé nebo aspoň dlouhodobé edge. Svým předchozím příspěvkem jsem v zásadě chtěl říci asi tohle: Existují různé přístupy k návrhu/work flow/backtestování/používání obchodních systémů, v zásadě ale spadají někam do následujících skupin: 1) Rozumím vnitřní struktuře procesu, který generuje vstupy pro můj OS (znám jak funguje trh „zevnitř“) tj. vycházím z REALITY (zejména trhu) a z POROZUMĚNÍ této realitě. Pokud v tom naleznu nějakou využitelnou neefektivitu, tak vím odkud a proč plyne moje edge a jaké jsou vyhlídky na to, že to bude fungovat v budoucnu. Bude to založeno na něčem, co nějak vychází z pricipu logiky věci. Na základě toho postavím systém. Potom nemusím nic optimalizovat, backtestovat (prakticky samozřejmě backtest provedu pro zjištění ostatních parametrů a abych se ujistil, že to tak opravdu funguje) a můžu být vcelku klidný při živém obchodování, že to bude fungovat bez větších zádrhelů víceméně stejně třeba celý život, nebo vím v jakém rozsahu se to bude pohybovat a proč. Vím tedy, že systém nemá dobré výsledky kvůli náhodě, ale kvůli využívání skutečného reálného edge. Vím potom, jestli je to edge časově stabilní nebo dočasné a na čem závisí. Jsem si plně vědom toho co dělám a proč. Tenhle přístup je mému srdci nejbližší, ale není to taková legrace jak to možná vypadá. 2) Nějakým jiným způsobem (datamining, optimalizace backtestu, pokus/omyl, ...) a to korektním způsobem zjistím pravidla a parametry obchodního systému, který vykazuje v backtestu dobré a robustní výsledky. Potom se snažím pochopit, jak a proč by tato pravidla a parametry měli vyplývat z reality. Pokud na to přijdu, tak jsem objevil edge jiným přístupem, ale vím, že ho mám. Důsledek je stejný jako u 1. přístupu. Jiný přístup, stejné výsledky. Pro mě taky schůdná cesta. 3) Nějakým jiným způsobem (datamining, optimalizace backtestu, pokus/omyl, ...) zjistím pravidla a parametry obchodního systému, který vykazuje v backtestu dobré a robustní výsledky, ale nepodaří se mi najít a pochopit realitu, ze které by to mělo vyplývat. Třeba proto, že díky použité metodě to není z principu možné, nebo na to prostě nepřijdu. Pak to můžu používat, ovšem s vědomím že nevím, jestli využívám nějaké reálné edge nebo jsou dobré výsledky jen dílem náhody. Robustnost z backtestu na tom nic nezmění – může jít jen o dočasnou „robustnost“. Nevím o ničem, jak odlišit takto „z vnějšku“ skutečné edge od náhody. To že jste provedli backtest na 100.000 obchodech a všechno je krásné a robustní ještě není žádnou zárukou, že to bude fungovat i v budoucnu. Totéž platí i pro forward testy. Záleží to na postupu při tvorbě systému a postupu při testování (počet stupňů volnosti, přeoptimalizace - zjištění výsledků z příliš velké množiny pravidel a parametrů bez adjustování výsledků z ohledem na to, atd.). Pokud se to udělá profesionálně, je tady šance i přesto, že neidentifikuji svoje reálné edge. Možný přístup, ale dobrý pocit bych z toho neměl, falešného zlata najdete mnohonásobně více, než pravého. Do téhle kategorie spadá většina mechanických/automatických systémů. Jejich životnost záleží na kvalitě provedení a na náhodě. 4) Naivní přístupy – zjistím nějakým způsobem pravidla a parametry obchodního systému, který vykazuje v backtestu „dobré“ výsledky, ovšem ignoruji při tom důležité zásady pro tvorbu a testování systému, nerozumím ničemu v pozadí trhů ani návrhu systémů a ani mě to nezajímá, hlavně když equity křivka krásně roste. Kašlu na nějaké testy robustnosti apod. Šance na úspěch: téměř nulová. Klasický postup všech začátečníků (PS: všichni si touhle fází prošli, protože zkušenost je nepřenositelná) Pokud walk forward jenom periodicky optimalizuje nějaké parametry, které s reálným edge nesouvisí, tak se jen adjustuje na minulá data a výsledky obchodování jsou jen dílem náhody. Pokud na to jdeš jinak, pak OK, jen nevím jestli to je ještě walk forward nebo nový cyklus vývoje dalšího systému, ale to je jedno. Na slovech nezáleží, důležité je rozumět tomu co děláš a proč. Zásadní pro přístup podle 2 a 3 je právě správný úhel pohledu, korektní postup a interpretace výsledků. To že mi to něco najde ještě neznamená, že to k něčemu je – rozumíme si, že :) Tohle všechno je také jen jedna část problému. Pokud dobrý systém v praxi špatně používáte (špatný risk management), tak je to na nic. Mít edge je podmínka nutná, nikoliv postačující. Mít dobrý risk management je podmínka nutná, nikoliv postačující. A pak ještě konzistence při používání a další věci. Když máte edge a dobrý risk management, tak je trading super zábava. V opačném případě to chce hledat dál. Risk management je rozhodně ta lehčí část. -
Diskuze k článku: Automatické obchodní systémy: životnost a risk-management (1/3)
příspěvek: Heron odpověděl na příspěvek uživatele Financnik.cz ve vláknu Finančník.cz - diskuze k článkům
sals3r0: Chtěl jsem to dát do tvého vlákna o predikci časových řad, ale sem se to možná hodí více. Zajímal by mě tvůj (nebo kohokoliv jiného) názor na následující hypotetický experiment: Řekněme, že bych ti dal časovou řadu (třeba OHLCV data, nebo cokoliv bys chtěl), která by byla generovaná čistě náhodným procesem v exaktním slova smyslu (a nikoliv s normálním rozdělením). Tato řada by měla ze statistického hlediska „všechny“ vnější podobnosti se skutečnými trhy (rozdělení s tlustými konci, shlukování volatility, návrat volatility výnosů k průměru, korelace volatility a objemu, absence autokorelace výnosů na větších TF atd.). Ty bys ale neměl informaci, že se jedná o náhodná data, to bych věděl jen já. Ponechme zatím stranou diskuzi jestli lze nebo nelze udělat náhodný generátor který to generuje a předpokládejme že ano (možný přístup k tomuto je přes Agent Based Modeling). Když si ta moje náhodná data zobrazíš do grafu, tak uvidíš všechny možné patterny TA – double top/bottom, head and shoulders, odrazy od Fibonacci levelů, odrazy od MA, trendy na všech time framech, range úseky, trendové kanály, kulaté hodnoty na cenové ose, které fungují jako S/R, klasické S/R, různé candlestick formace, mean reverting, patterny pro RSI, CCI atd. – prostě uvidíš cokoliv (subjektivně i objektivně pomocí SW pro vyhledávání objektivně definovaných patternů). To pochopitelně uvidíš i na datech generovaných třeba geometrickou náhodnou procházkou s normálním rozdělením, což si můžeš ověřit třeba v excelu. Záměrně jsem proto uvedl „složitější“ náhodný proces, abych ti zabránil sofistikovanějšími postupy odhalit, že se jedná o „falešná“ náhodná data a ne o skutečný trh. Ty teď na moje data nasadíš nějaké svoje metody pro předpovídání dalšího vývoje, které bez ohledu na sofistikovanost použité metody VŽDY v principu vycházejí z minulých dat a z toho, že rozpoznají v uvedených datech „nějaký obecný pattern“ – nikoliv nutně pouze cenový – ve smyslu že když se stalo tohle, tak pak je statisticky významně větší pravděpodobnost, že se v nějakém časovém horizontu stane něco jiného. Oprav mě prosím, pokud je tomu jinak. Vzhledem k tomu, že tvůj „backtest“ nebo „učení“ proběhlo na KONKRÉTNÍM a KONEČNÉM vzorku dat a vzhledem k tomu, že náhodný proces z principu neobsahuje žádnou šanci na předpovězení budoucích hodnot z minulých hodnot (předpovědní hodnota jakéhokoliv statistického „paternu“ je pro hodně velkou nebo „nekonečnou“ délku dat 50/50), tak přesto téměř JISTĚ při backtestu objevíš nějaké patterny se statisticky významnou hodnotou úspěšnosti - pokud projedeš dostatečně velkou množinu pravidel a parametrů. Ty „úspěšné“ patterny ale půjdou vždy pouze na vrub náhodných statistických fluktuací, tj. konkrétnímu průběhu mnou dodaných náhodných dat pro backtest a říká se tomu přeoptimalizace, curvefitting apod. Trendy nebudou ani perzistentní, ani antiperzistentní z dlouhodobého hlediska, leda tak z hlediska konkrétního „relativně krátkého„ backtestovaného vzorku. Pokud bys na těch „patternech“ nebo “pravidlech pro obchodování“ založil obchodní systém, tak by mohl klidně třeba chvíli vydělávat, třeba i delší dobu, ale z principu věci z dlouhodobého hlediska by byl na nic. Vzhledem k mean reverting by pravděpodobně při dobrých výsledcích v backtestu šel ke dnu hned po nasazení na živá data (tj. aplikaci na další kus náhodné časové řady, kterou bych ti dodal později). Ty tedy aplikuješ své metody, najdeš patterny (vstupy a parametry pro „předpovídání budoucnosti“) a s výkřikem heuréka se vrhneš na „trh“. Jak to dopadne je z krátkodobého hlediska ve hvězdách, ale z dlouhodobého hlediska je to bez šance. A teď druhá varianta. Co kdyby ta mnou dodaná data nebyla čistě náhodná, ale obsahovala nějakou využitelnou informaci, „zašuměnou“ náhodnou složkou. Z vnějšího statistického pohledu by se neodlišovala od těch prvních náhodných. Tvoje metody a systémy by také našly nějaké statisticky významné „vstupy, patterny a pravidla“. Jaká je šance takového systému ve srovnání s tím předchozím případem náhodných dat? Klíčová otázka: Jak poznáš, jestli tyhle nové patterny a pravidla nevychází také pouze z náhodných statistických fluktuací a že skutečně využívají část informace, obsažené v backtestovací množině? Můžeš si samozřejmě udělat Monte Carlo simulace a intervalové odhady apod., ale faktem zůstává, že to stejně nepoznáš, resp. ne včas. Výše popsané je mimo jiné v kostce důvod, proč mají obchodní systémy obecně krátkou životnost - protože vycházejí nikoliv z nějakého skutečného „edge“ (natož časově stabilního), ale z náhodných statistických fluktuací tj. nejčastěji z iluze. Pod pojmem „pochopení edge“ mám na mysli využití částečné neefektivity tj. částečné nenáhodnosti trhu skrze porozumění struktuře trhu tj. charakteru procesu, který generuje časové řady cen, volume apod. Edge v žádném případě neznamená, že budeš mít samé výhry, ale že z dlouhodobého hlediska jsou karty rozdány ve tvůj prospěch. Z čistě náhodného procesu žádné edge nejde vytěžit ani sebesofistikovanější metodou. Samozřejmě že na skutečných datech teoreticky lze narazit na edge i tvým přístupem, ale jak říkám, nikdy nebudeš vědět, jestli to není díky náhodné fluktuaci a při menším drawdownu systém zbytečně odstavíš díky pochybnostem. Taky lze s libovolným systémem mít štěstí klidně i dlouhou dobu, pokud bude trh naladěn na stejnou notu jako obchodní systém. Sám uvaž, jestli např. tenhle problém může nějak vyřešit často doporučovaný walk forward přístup. Není to jen nějaká sranda poznámka na okraj. Jedná se o zásadní problém technické analýzy, backtestování, návrhu obchodního systému, automatických obchodních systémů, obecně systematického tradingu jako takového. Výše uvedené je sice pouze můj osobní pohled na věc, ale není nijak osamocený. Zajímal by mě tvůj (nebo kohokoliv) pohled na tenhle problém, nebo jak to řešíš. Díky. -
fuxo: Pokusím se to říci ještě trochu jinak. Když budu mít pro backtest například 100 vzorků dat (každý vzorek bute třeba 10.000 cenových barů testovaného trhu) a já udělám 100 backtestů (jeden backtest pro každý vzorek), tak dostanu 100 různých hodnot PF. V praxi budou některé hodnoty PF podobné. Když si potom těchto 100 získaných hodnot PF vynesu do histogramu četnosti, tak dostanu sampling distribution, které bude vypadat jako krtčí hromádka, ale bude mnohem užší a špičatější. Tím mám představu o tom, kam nejčastěji PF spadne a kolik procent těchto hodnot PF leží v nějakém rozmezí od střední hodnoty (vidím ze sampling distribution). Protože živé obchodování můžu považovat za další vzorek, tak můžu odhadnout jak velké PF a s jakou pravděpodobností asi bude (ze živého obchodování na živých 10.000 barech) tj. např. že s pravděpodobností 95% bude ležet někde mezi 0,9 až 2,6. Na základě sampling distribution (kromě jiného) se tedy můžu rozhodnout jestli to obchodovat živě nebo radši ne. Nevím jaká data budou v živém obchodování, ale pokud považuji 100 testů za dostatečné, tak si můžu udělat představu jaký asi bude výsledek (intervalový odhad). Praxe je ale taková, že nemám k dispozici 100 takových desetitisícových vzorků. Často máme jen jeden. Proto si musíme vypomoci tím, že z něj uděláme 100 vzorků tím, že ten jeden vzorek vždycky zamícháme a tím dostaneme nový vzorek dat. V praxi se pro to míchání používá Monte Carlo metoda nebo Bootstrap (každá má své plusy a mínusy). Také se v praxi používá pro získání sampling distribution a tedy pro intervalové odhady parametrů (např. PF) mnohem více než 100 vzorků, většinou spíše tisíce nebo desetitisíce. Pro ruční práci to rozhodně není. Není to ideální přístup, ale nic lepšího zatím vymyšleno není (pokud je mi známo). Tady také vidíš, proč někdo používá backtest (in sample) a potom ještě formward test (out of sample) - chce si udělat lepší představu o tom, jaké to bude mít parametry než se pustí do dalšího vzorku - live sample. Jestli dva vzorky stačí, to ať každý posoudí sám - záleží na čem je ten systém postaven. Tohle vše je přístup přes TA a lze k tomu jistě přistupovat i jinak. Olympusko se tím nějak více zabývá nebo chce zabývat ve svém vlákně.
-
fuxo: Velmi správná poznámka. Protože je to nad rámec úvodu do tématu pro úplné začátečníky, tak jsem to zatím nenakusoval. Možná že ten příklad s konkrétní distribucí PF pro konkrétní jeden baktest byl spíš zavádějící, chtěl jsem jen ukázat že aktuální nebo průměrná hodnota není všechno. V praxi je to asi k ničemu (dělat si ten histogram z jednoho backtestu tak jak jsem to napsal) a dělá se to trochu jinak. Pořadí obchodů resp. pořadí vstupních dat je třeba brát v úvahu (pokud chceš mít "jistotu", že výsledek backtestu není jen dílem náhodné aktuální konfigurace vstupních dat). To co dostaneš z backtestu je jen jeden vzorek. Prakticky se to nejčastějí řeší buď přes Monte Carlo nebo Bootstrap. Uděláš permutace / promíchání vstupních dat a sleduješ co to udělá s PF - dostaneš "sampling distribution", tj. dostaneš distribuční rozložení PF z různých permutací a můžeš vidět, do jakých mezí by s jakou pravděpodobností (intervaly spolehlivosti na zvolené hladině významnosti) mělo PF takového systému padnout. Výborně je to popsáno a vysvětleno v Aronsonovi, na kterého jsem už někde dával odkaz. Včetně toho na co si při praktické implementaci dávat pozor a proč. Platí to obecně, ne jen pro PF.
-
Souvislost efektivity trhů a problému P vs NP (jen pro otrlé jedince) Vzhledem k tomu, že jsem se nechtěně trochu otřel o oblast random walk a zprostředkovaně o téma efektivnosti trhů, tak bych chtěl poznamenat, že tahle oblast vůbec není tak jednoduchá a přehledná, jak na první pohled možná vypadá. Existuje velké množství protichůdných názorů a „důkazů“ pro obě možnosti. Nechtěl bych tohle téma v žádném případě otevírat, jen bych se chtěl podělit o zajímavý článek „Maymin, Philip - Markets are efficient if and only if P = NP„ (viz příloha), kde je dávána do souvislosti velmi originálně efektivita trhů a problém P vs NP - jak by důkaz jednoho zároveň mohl posloužit k důkazu druhého. Na něco podobně originálního člověk nenarazí každý den. Je to napsáno celkem srozumitelně. Pro ty kdo nevědí co je problém „P vs NP“, tak to neřešte. K tradingu to nepotřebujete. Spadá to do kategorie velmi širokých souvislostí.
-
Jogo: Ano, uvažuješ správným směrem. Použití SL ani PT neovlivňuje střední hodnotu PnL tj. „výnosnost systému“, ovšem pouze „za jinak stejných podmínek“ a pokud v datech není přítomen trend tj. backtestujeme na detrendovaných datech. Za jakých „jinak různých“ podmínek mají vliv na střední hodnotu PnL je rozebíráno v přiloženém článku. Jde v zásadě o koincidenci SL/PT s nějakým trendem v datech. Totéž platí pro proměnlivé hodnoty SL/PT nebo pro trailing. Protože pro detrendovaná data nemění střední hodnotu PnL, tak je jedno jestli je nula nebo jiná –nezmění se, jen se rozložení zdeformuje. Tím že se nezmění střední hodnota je míněno také to, že celková plocha pod křivkou vlevo od střední hodnoty bude stejná před i po použití SL/PT. Stejné platí i pro plochu vpravo od střední hodnoty. K tomu obrázku – je možné že jde o dramatizační efekt, aby to bylo pořádně vidět (oblast B), nebo se jedná o data s trendem. Smyslem bylo poukázat na to, že použití SL/PT nepřináší jen výhody (větší střední hodnotu, menší volatilitu), ale může přinášet i nevýhody. To záleží na kontextu použití tj. zejména na trendu (drift). To není žádná novinka - použití PT v trendu je horší, než použití trailing SL. V range trhu je to naopak. To co jsem napsal já je jen částečný výtah ze článků. Líbilo se mi ale jak je to v nich popsané a že jsou tam hezké obrázky pro udělání si představy. Jestli je nějaká souvislost mezi U rozdělením HoD a deformací rozdělní PnL pomocí SL/PT? Nevím, já tam žádnou podobnost ani souvislost nevidím, takže se k tomu nebudu vyjadřovat.
-
onlyx: K tomu jestli trhy jsou nebo nejsou nějakým typem RW jsem se vyjadřovat nechtěl a jestli něco takto vyznělo, tak to nebylo záměrem. Rozhodně to neměl být žádný důkaz toho, jestli trhy jsou nebo nejsou čistě náhodné. Omlouvám se. Chtěl jsem jen ukázat následující: - když vycházíte z chybného předpokladu (viz tvrzení na začátku), tak o závěru tvrzení z předpokladu vyplývajícího nemůžete nic tvrdit. Možná jsou trhy RW z nějakého jiného důvodu, možná že z nějakého jiného důvodu nejsou čistě RW. - narážkou na Larryho jsem myslel, že informace uvedená v knize nejspíš k ničemu nebude - pokud jde o rozdíl mezi skutečnými daty a rozdělením geometrické RW s normálním rozdělením, tak je jasné, že se lišit musí, protože skutečné trhy nemají normální rozdělení - mají tlusté konce a jsou špičatější. Skutečné trhy by klidně mohly být nějakou jinou formou RW (než geometrickou s normálním rozdělením), která má rozdělení více odpovídající skutečnost. Zároveň to ale neznamená, že by nemohly být minimálně částečně "nenáhodné". Nejsem si jistý, jestli se dá rozdíl mezi geometrickou RW s normálním rozdělením a skutečností využít (bez dalšího hlubšího prozkoumání). Možná ano, možná ne. K tvé otázce: Pokud by se ti snad podařilo nalézt OS, který funguje (má kladnou střední hodnoti rozdělení PnL s přihlédnutím k margin of error) na skutečně čistých RW datech s nulovou střední hodnotou (tím myslím na detrendovaných datech, minimálně 10.000 různých průběhů RW, dostatečně velký vzorek dat a obchodů), pak se brzy staneš nejbohatším a nejslavnějším člověkem v historii lidstva, vesmíru a vůbec. Jako bonus pošleš na smetiště dějin několik zavedených vědeckých oborů, které se těší velké vážnosti. Přirovnal bych to k nezvratnému důkazu, že neplatí zákon zachování energie nebo k sestrojení funkčního perpetum mobile. Netvrdím, že to není možné. Věda je založena na možnosti falsifikace. Teoreticky je možné všechno, jenom něco je málo pravděpodobné - někdy opravdu velmi velmi málo pravděpodobné. RW jsou "čistý šum", který neobsahuje žádnou informaci. Pokud dokážeš získat pomocí OS informaci odněkud, kde žádná nebyla a není, pak budu muset radikálně přehodnotit své představy o tom, jak tenhle svět funguje. Kromě toho RW je jen vnější popis, ne model proč a jak funguje nebo nefunguje trh. A moje odpověď na otázku: Ano, takový systém by nepochybně byl profitabilní i na reálných trzích :) Pravda, můj názor a zkušenost jsou, že trhy nejsou vždy, všude a na všech time framech čistě náhodné, a že obsahují tu a tam využitelnou informaci. Jinak bych se do toho ani nepouštěl, kdybych si byl "jistý" že není šance na úspěch. Takže v podstatě jsi došel ke stejnému závěru jako já. Neměl bys ale k němu dojít na základě mého příspěvku, ten je na takové závěry příliš povrchní a neobsahuje pro tento závěr dostatečné informace.
-
Střípek souvislosti mezi povahou tradera a jeho výsledky Koho by zajímalo, jak hodně nebo málo ovlivňuje něčí osobnost jeho výsledky v tradingu, tak doporučuji k přečtení přiložený článek „Tharp, Van K. - Personality Type and Trading“. Pro ty kdo neznají svůj typ osobnosti podle typologie MBTI, tak se dá vygooglit včetně testů. Dobré jsou knížky od Michala Čakrta „Typologie osobnosti pro manažery“ a „Typologie osobnosti / Přátelé, milenci, manželé, dospělí a děti“. Nenechte se zmást jejich názvy a odradit začátkem první jmenované, popisují jak různé typy lidí vnímají svět, zpracovávají informace, reagují na podněty, mají svůj žebříček hodnot a vlastní (typový) jazyk a přístup k okolí i k sobě.
-
Střípek souvislosti konzistence výnosů a profit faktoru Koho by zajímalo, jak souvisí konzistence výnosů, velikost expectancy a velikost profit faktoru, tak tady to máte na Richardově webu přehledně i s obrázky: www.movethemarkets.com/blog/2007/01/28/how-to-be-consistently-profitable-in-the-markets/ Kdo neznáte tenhle web, tak vřele doporučuji (míněno začátečníkům a středně pokročilým, ale na své si občas přijdou i zkušenější borci). Obsahuje mnoho velmi zajímavých článků k různým aspektům obchodního systému, riziku, money managementu apod. Projděte si i starší věci v archivu. Mnoho velmi zajímavých a užitečných postřehů má na svém webu také Max Dama.
-
Úvod do obchodního systému a Profit Factor (pro úplné začátečníky, část 3/3) Důležité souvislosti: Jestli váš systém k něčemu je, tak musí mít PF >1. Pokud nemá, tak vás žádný position sizing (money management) nemůže zachránit. Zvyšovat PF můžete jen třemi způsoby: 1) větší procento ziskových obchodů (hledat obchody s vysokou pravděpodobností úspěchu) 2) větší průměrný zisk u ziskových obchodů (hledat obchody s vysokým potenciálem zisku) 3) menší průměrná ztráta u ztrátových obchodů (hledat obchody s nízkým rizikem, kde můžete mít relativně malý SL vůči potenciálnímu zisku) Pokud váš systém má/využívá nějaké „edge“, pak se to nutně projeví také v hodnotě PF. Při backtestu byste měli nejprve testovat systém pro 1 kontrakt, jinak budou některé výsledky (PF) zavádějící. To že zjistíte při backtestu, že má váš systém PF >1 ale ještě neznamená, že máte vyhráno. Proč? Uvědomte si, že PF závisí na počtu provedených obchodů, ze kterých se počítá. Přidáte jeden obchod a PF se mírně změní, přidáte další a PF se zase trochu změní. Backtest vám většinou ukáže jen snapshot pro konkrétní backtestovaný počet obchodů. Vy se musíte také podívat na to, jak se PF postupně měnil s rostoucím počtem obchodů tj. jak se měnil PF v „čase“ a jaký byl jeho průměr. To že teď právě byl PF = 1,25 vám nepomůže, když průměrně byl PF = 0,9. Průměr PF vám sám o sobě ale také ještě nestačí. Pokud si vynesete PF pro různé počty obchodů do grafu (uděláte si tzv. histogram četnosti), tak dostanete nějakou křivku připomínající krtčí hromádku, buřinku nebo čepici Harryho Pottera – to záleží na vnitřku vašeho systému. Na vodorovné ose bude velikost PF a na svislé ose počet případů, kolikrát bylo příslušné hodnoty PF dosaženo. Je sice hezké když nejčastější hodnota nebo průměr PF byl třeba 1,1, ale když 80% hodnot PF leží níže než 1, tak je to na zamyšlení, jestli se to dá použít. Vaším cílem je, aby co největší počet hodnot PF byl větší než 1. Čím více, tím lépe. Je jasné, že když budete zvyšovat průměrné PF, tak se „krtčí hromádka“ bude „posouvat nebo roztékat “ celkově doprava. Velmi důležitá věc pro obchodování je konzistence – jednak konzistentní přístup k obchodování (dodržování pravidel atd.), ale hlavně konzistence ve výsledcích tj. provedených obchodech. Konzistenci si můžeme definovat jako počet období, kdy OS vygeneroval nějaký zisk ku celkovému počtu všech období, kdy byl v provozu. Na volbě délky období nezáleží. Poznamenávám, že existují velmi důležité souvislosti mezi PF a konzistencí výsledků (téma na samostatný příspěvek). Z distribuce PF tak můžete vidět, jestli jsou výsledky systému dílem náhody nebo jste přišli na něco užitečného. Ještě několik poznámek na závěr: Rozlišujte prosím funkční systém od obchodovatelného systému. Funkční systém musí mít mimo jiné především takové rozdělení PF, aby byla průměrná hodnota PF >1 (a ideálně aby co nejvíce hodnot PF bylo >1 kvůli robustnosti). Obchodovatelný systém musí mít totéž, ale navíc ho aplikujete na takovém trhu, kde velikost poplatků apod. vám nezabrání v použití OS. Proto backtestujte systém nejprve bez poplatků, jinak to poplatky zkreslí. Funkční systém, který nevyždímá zisky z jednoho konkrétního trhu (kvůli poplatkům) vám může zajistit živobytí na jiném, vhodněji vybraném trhu a vy třeba zbytečně zahodíte užitečnou myšlenku. Protože drtivá většina systémů nemá žádné edge, tak je jejich PF téměř symetricky rozdělen kolem hodnoty 1, resp. průměrná hodnota PF bude jen kousek nad 1 (důvod proč někdo OS považuje za úspěšný). To je ale často bohužel způsobeno spíše pouhou náhodou, než nějakým systematickým využitím edge. Proto také mj. nejde z nějakého ztrátového systému udělat ziskový tím, že obrátíte pravidla pro long/short nebo prohodíte stop loss a PT. Kde nic není, tam nic nenajdete. A pokud nenarazíte na žádné edge, tak jakákoliv snaha o zvýšení W% vám proporcionálně sníží win/loss ratio a naopak, takže si nijak nepomůžete. Také si uvědomte, že počet obchodů vyplývající z backtestu je jen malou součástí obchodů, které váš systém vygeneruje v budoucnosti během svého používání. Proto je možné, že získaný histogram PF není moc reprezentativní vzorek skutečného rozdělení PF ze všech obchodů (backtestových + budoucích). Když budete mít relativně malý vzorek obchodů z backtestu, tak skutečné rozdělení hodnot PF může být někdy velmi odlišné. Profit faktor není „jediný“ způsob nebo „nejlepší způsob na světě“ jak měřit „kvalitu“ systému. Má také svoje slabé stránky – nepopisuje vše důležité. Patří ale mezi ty základní a velmi důležité metriky, které byste rozhodně měli brát v potaz a rozumět co je za nimi. Výše uvedené není vyčerpávajícím popisem všech souvislostí kolem PF, pouze to hlavní na co jsem si zrovna vzpomněl. Snad vám to trochu pomohlo v orientaci.
-
Úvod do obchodního systému a Profit Factor (pro úplné začátečníky, část 2/3) Co by nás mohlo zajímat? Protože nám jakožto obchodníkovi jde hlavně o zisky, tak si nejprve vyjádříme celkový zisk: P = SW – SL Aby byl náš OS k něčemu užitečný, tak celkově chci mít více, než jsem tam vložil. Proto musí celkový zisk převýšit celkovou ztrátu, tj. vyžaduji P > 0 Také si můžeme vyjádřit expectancy, tj. jaký je průměrný zisk (v USD) na 1 každý obchod: E = P/n E = (SW – SL)/n E = (AW*nW – AL*nL)/n E = AW*(nW/n) – AL*(nL/n) E = AW*W% - AL*L% Vidíme, že po úpravě už se nám do toho dostala „pravděpodobnost“ tj. W% a L%. Je jasné, že když bude P>0, tak to samé bude platit i pro E, jen to bude vyjádřeno pro jeden obchod. Potíž s využitím P a E je tahle: Jeden OS má celkové zisky 1.000 USD a ztráty 990 USD, a jeho celkový zisk je tedy 10 USD. Druhý systém má celkové zisky 1.000.000 USD a ztráty 999.990 USD, takže stejný zisk P = 10 USD. Intuitivně vidíme, že ty systémy nejsou stejné co do kvality, i když dávají stejný celkový zisk P. Celkový zisk P tedy není vhodnou metrikou pro kvalitu systému. Předpokládejme, že uvedené systémy měli také stejný počet obchodů a tedy mají i stejnou expectancy E. Expectancy tedy také není příliš vhodné měřítko, protože ukazuje to samé co P, jenom přepočítané na jeden každý obchod. Proto je vhodné zavést lepší metriku pro měření „ziskovosti / efektivity“ systému, a to profit faktor PF: PF = SW / SL tj. podíl celkových zisků k celkovým ztrátám, nikoliv rozdíl jako u P Můžeme to dále upravit: PF = (AW*nW) / (AL*nL); vynásobíme výrazem (1/n)/(1/n) PF = (AW*(nW/n))/(AL*(nL/n)) PF = (AW*W%)/(AL*L%) PF = (AW*W%)/(AL*(1-W%)) PF = (AW/AL)*(W%/(1-W%)) ... velmi důležité! Výše uvedené příklady dvou systémů se stejným E budou mít naprosto jiný PF. Je vidět, že když je systém celkově ziskový, tak P>0; E>0 a PF >1. Pokud je systém ztrátový, tak má P Tohle je základ, který je třeba si uvědomit. Potřebujeme naprosto nutně, aby náš systém měl PF > 1, jinými slovy PF>1 je „podmínka nutná, nikoliv postačující“ pro funkční (rozuměj generující zisky, které z dlouhodobého hlediska v průměru převažují nad ztrátami) obchodní systém. Z posledního vyjádření PF je vidět velmi důležitá věc: PF závisí pouze na třech věcech – na win rate (tj. na procentu ziskových obchodů W% ku procentu ztrátových obchodů) a na average win/loss ratio (tj. poměr průměrného ziskového obchodu AW k průměrnému ztrátovému obchodu AL). To jsou jediné věci (W%, AW, AL), které můžou ovlivnit velikost PF. Vidíte, že tu zatím nikde nebyla řeč o počtu obchodovaných kontraktů resp. position sizingu / money managementu. To proto, že výše uvedené se týká jednoho kontraktu, resp. nějaké zvolené „jednotky“ velikosti pozice – prostě pokud by byly vaše zisky a ztráty generovány různým počtem kontraktů, tak je musíte přepočítat na jeden kontrakt.
-
Úvod do obchodního systému a Profit Factor (pro úplné začátečníky, část 1/3) Nejspíš už to tady bylo několikrát vysvětlováno, takže jen zopakování pro ty kdo to nevědí. Chtěl bych se pokusit vysvětlit úplnému začátečníkovi co je to profit faktor, jaký má vztah k jiným metrikám zisku, proč je důležitý a jak souvisí s backtestem, konzistencí, tím co z něj můžeme zjistit apod. Pokusím se to napsat tak polopaticky, jak jen dovedu. Co je obchodní systém: Obchodní = používáme ho pro obchodování Systém = má nějakou hranici, která ho odděluje od okolí; má nějakou strukturu tj. nějaké části (subsystémy) ze kterých se skládá a funkční vazby mezi nimi; a má nějaké vstupy a výstupy Necháme teď stranou vnitřní strukturu OS (jaké komponenty obsahuje a jak jsou uspořádány a provázány) a podíváme se na systém z vnějšku. Na určité úrovni abstrakce se na obchodní systém (OS) můžeme dívat jako na krabičku, kde do ní na jedné straně vstupují nějaká data (ceny, volume, jiné trhy, fundamentální data, ...) a na druhé straně z krabičky vypadávají ukončené obchody ve tvaru +100 USD, -80 USD, +30 USD, +124 USD, -25 USD .... (plus je zisk, mínus je ztráta). Jinými slovy, vypadávají z ní čísla a to celkem důležitá, protože jsou to naše peníze. Pokud používáte OS na úrovni AOS, tak musíte vstupní informace kvantifikovat tj. převést je na čísla. Pak OS transformuje vstupní čísla na výstupní čísla (nebudeme to zatím komplikovat žádnou zpětnou vazbou). Hlavním cílem obchodníka je navrhnout vnitřek systému spolu s výběrem vhodných vstupů tak, aby na výstupu systému byly z dlouhodobého pohledu zisky, které budou konzistentně převyšovat ztráty. A pak ho samozřejmě používat. Vzhledem k tomu, že na výstupu jsou pouze provedené obchody, tak to jak a jestli je OS „kvalitní“ musíme poznat / měřit právě z jeho výstupů, tj. z výstupní odezvy OS na vstupní podněty. Teď trošku lehké matematiky a pojmů, bez kterých to nepůjde. Protože existuje celkem hodně různých pojmů označujících totéž, nebo naopak každý si pod stejným pojmem představuje něco jiného, tak tady uvedu „svoji“ terminologii – dávám přednost pojmům, které co nejlépe vystihují svůj obsah a nematou svým názvem. Na označení ve skutečnosti zase tolik nezáleží, jde hlavně o pochopení souvislostí. Definice základních pojmů a označení: nW ... number of win (počet ziskových obchodů) nL ... number of loss (počet ztrátových obchodů) SW ... sum of win (součet zisků ze všech ziskových obchodů, součet všech zisků) SL ... sum of loss (součet ztrát ze všech ztrátových obchodů, součet všech ztrát) n ... number of trades (celkový počet všech obchodů bez rozdílu, jestli byl ziskový nebo ztrátový) W% ... winning percentage, (procento ziskových obchodů) L% ... losing percentage (procento ztrátových obchodů) WLR ... (average) win/loss ratio (poměr průměrného zisku k průměrné ztrátě) - někdo to ne zcela správně zaměňuje s RRR tj. s reward to risk ratio AW ... average size of winning trades (průměrný zisk při ziskovém obchodu) AL ... average size of losing trades (průměrná ztráta při ztrátovém obchodu) P ... profit (celkový zisk z celé série obchodů) E ... expectancy (očekávaný průměrný zisk na jeden každý obchod) PF ... profit factor, reward factor (profit faktor) To by pro začátek stačilo. Důležité je si uvědomit jak to spolu souvisí. První čtyři uvedené (nW, nL, SW, SL) jsou základ, ze kterých vypočítáme všechno, co potřebujeme. Základní vztahy: n = nW + nL W% = nW/n L% = nL/n W% = 1 - L%, tj. každý obchod zařadím buď do kategorie zisk nebo ztráta, nikam jinam AW = SW / nW AL = SL / nL WLR = AW / AL
-
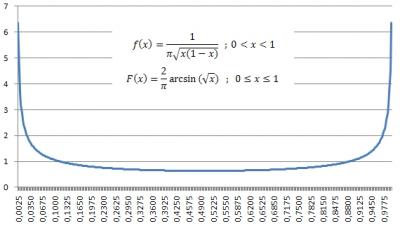
Rozdělení High of Day (HoD) během seance Možná jste se někdo setkali (já tedy několikrát) s následujícím názorem: „Kdyby byly trhy náhodná procházka, tak by měly rovnoměrné rozdělení HoD během seance. Protože je ale skutečnost taková, že HoD má rozdělení ve tvaru U, tak z toho plyne, že trh nemůže být náhodná procházka (a my tedy máme jistotu, že existuje profitabilní systém, který tuto odchylku od náhodného průběhu může využít). „ Poznámka: High of Day – nejvyšší hodnota ceny dosažená během obchodní seance. Seanci rozdělíme na několik stejných časových intervalů, např. po 15 minutách a pro třeba 1000 dnů si zaznamenáme, do kterého 15 minutového intervalu spadne HoD. Nejvíce jich bude na obou krajích - u open a close seance, nejméně uprostřed seance. Rovnoměrné rozdělení by znamenalo, že do každého z časových intervalů padne zhruba stejný počet. Na první letmý pohled vypadá „logicky“, že by mělo být rozdělení rovnoměrné, ale nějak mi intuitivně neseděl příliš velký rozdíl mezi skutečným rozdělením a „teoretickým“ rovnoměrným rozdělením. Trochu jsem pohledal a zamyslel se nad tím a zjistil jsem následující: HoD náhodné procházky (např. geometrické s proměnlivou délkou kroku s normálním rozdělením) NEMÁ rovnoměrné rozdělení HoD, ale jiné. Konkrétně je dáno tzv. ascsinovým zákonem (arcsine law) a vypadá jako více nebo méně zploštělé U (záleží na kolik intervalů si rozdělíte seanci). Stejné rozdělení má: - rozdělení High seance - rezdělení Low seance - rozdělení podílů doby strávené nad úrovní (cenou) open seance ku celkové době seance - rozdělení podílů doby strávené pod úrovní (cenou) open seance ku celkové době seance - rozdělení doby posledního přechodu přes úroveň (cenu) open seance Zdůrazňuji, že mluvím o náhodné procházce. Dojde se k tomu přes stavový strom, kombinatoriku a pravděpodobnost (jaký podíl cest stromem vede ze začátku do konce a přitom se nedostane pod nějakou úroveň) a pak přes Stirlingovu aproximaci ke spojité distribuční funkci a hustotě pravděpodobnosti. Případní zájemci ať si detaily dohledají v učebnicích statistiky nebo třeba v „Lesigne, Emmanuel – Heads or Tails“. Ty teoretické výsledky pro náhodnou procházku jsem si ověřil simulacemi v excelu a sedí to nejen teoreticky, ale i prakticky. Skutečný trh se ale trochu liší od náhodné procházky. Když si třeba vynesete graf rozdílu (časové vzdálenosti) mezi HoD a LoD náhodné procházky a porovnáte to se skutečným trhem, tak se od náhodné procházky liší - v některých místech je menší (možná významně) a někde větší (možná významně). Zajímavé je, že skutečný graf tohoto rozdílu je hodně podobný pro odlišné trhy i pro dost odlišná období (místa kde se liší a o kolik). Je to dáno tím, že trhy nemají na rozdíl od geometrické procházky normální rozdělení, ale mají fat /heavy tails a jsou špičatější, nebo je to něčím jiným? Je to k něčemu? Nevím, možná někomu k něčemu ano. Jednak to uvádí na pravou míru chybné tvrzení uvedené na začátku. U křivka pro rozdělení HoD a LoD neimplikuje, že se nejedná o náhodnou procházku. Pokud byste snad měli strategii typu „při open seance jdu podle prvního baru long/short a při každém dalším průchodu přes úroveň ceny open reverznu pozici abych byl vždy na správné straně trhu (vzhledem k open), výstup na close seance“, tak si můžete udělat představu, jak se to asi bude chovat a může to třeba na něco být užitečné, např. po kolika reverzech to odpískat, když se evidentně nejedná o typ dne, který chcete využít. Všechno výše uvedené v celém příspěvku platí nejen pro denní seance (třeba RTH u futures), ale obecně pro libovolný časový interval, který má daný začátek a konec – např. týden, měsíc. Jo, a taky potom můžete vidět v trochu jiném světle to, co Larry Williams popisuje na str. 33 – 39 v knize Dlouhodobá tajemství krátkodobých obchodů. Cituji jeho závěr „Nesnažte se s těmito pravidly polemizovat. Jsou gravitačním zákonem, ovládají pohyb cen akcií a komodit...“ a já bych jen skromně dodal „a také náhodné procházky“ . Ještě malá poznámka: Nepleťte si to s U rozdělením volume a volatility během dne. To je trochu o něčem jiném. Pro případné zájemce přikládám dva články - „Acar, Emmanuel a kol. - Timing the highs and lows of the day“ (upozorňuji na tiskovou chybu ve vzorci v článku – místo arctg má být správně arcsin). Téměř identické obrázky pro rozdíl HoD a LoD jsem viděl jinde pro ES za období 2007-2009. Druhý článek je „Cohen, Joel E. - How Is the Past Related To Future“, který krásně popisuje tři případy, jak jednoduchý proces může generovat naprosto protiintuitivní výsledky. Moc hezké čtení, jen kvalita obrázků je mizerná. Je to z roku 1982, takže žádný div.
-
Merkur1: Z tvého příspěvku si nejsem moc jistý, jestli jsi pochopil co jsem chtěl připomenutím Čebyšeovovy nerovnosti sdělit. Prosím aby sem Airmike nakopíroval ten vysvětlující příklad z chatu (snad to pomůže - neviděl jsem ho). Není to o Bollinger Bands, i když se to tam dá taky použít.